 Raphael Schwinger
Raphael SchwingerIntroduction to Reinforcement Learning
Foundations, Challenges, and the Ecosystem
Welcome to the first chapter of Introduction to Deep Reinforcement Learning. This course will take you from the foundations of sequential decision-making to modern deep RL algorithms. Whether your goal is research, industry applications, or simply understanding how modern AI systems are trained, this chapter provides the conceptual groundwork you will need.
We begin by defining what reinforcement learning (RL) is and how it differs from other machine learning paradigms. We then survey landmark successes, discuss the core challenges that make RL both difficult and fascinating, and close with a practical overview of the research environments, software libraries, and learning resources available to you.
Slides for this chapter (open full screen).
What is Reinforcement Learning?¶
Reinforcement learning is a computational framework for learning to make sequential decisions through interaction Sutton & Barto, 2018. Unlike supervised learning, where a model learns from a fixed dataset of labeled examples, an RL agent learns by acting in an environment and observing the consequences of its actions. The agent receives numerical rewards that signal how well it is doing, and its objective is to discover a policy — a mapping from situations to actions — that maximizes the cumulative reward over time.
This learning-by-interaction paradigm draws inspiration from behavioral psychology, where organisms learn to associate actions with outcomes through trial and error Sutton & Barto, 2018. The key distinguishing features of RL compared to other branches of machine learning are:
No supervisor: The agent is not told which action is correct; it must discover good actions by trying them.
Delayed rewards: The consequences of an action may not be apparent until many time steps later.
Sequential decisions: Current actions affect future states and, therefore, future rewards.
Exploration is required: The agent must actively try new actions to discover which ones lead to high rewards.

Figure 2:The agent-environment interaction loop. At each time step , the agent observes state , selects action , and receives reward and next state from the environment.
Deep reinforcement learning (DRL) extends this framework by using deep neural networks to approximate the key components of an RL system — policies, value functions, or environment models — that would otherwise be intractable to represent in high-dimensional or continuous domains Mnih et al., 2015. Classical RL algorithms rely on tabular representations or hand-crafted features, which limits them to problems with small, discrete state and action spaces. Deep RL removes this bottleneck: a convolutional network Fukushima, 1980LeCun et al., 1998 can map raw pixels to action values, a recurrent network can maintain memory over long horizons, and a policy network can output continuous-valued motor commands. This marriage of deep learning’s representational power with RL’s decision-making framework is what enabled agents to master Atari games from pixels, defeat world champions at Go, and control robotic hands with human-level dexterity — achievements we review later in this chapter.
Formalization as a Markov Decision Process (MDP)¶
The standard mathematical formalization of the RL problem is the Markov Decision Process (MDP) Puterman, 1994Sutton & Barto, 2018. An MDP is defined by the tuple , where:
is the state space, the set of all possible states the environment can be in.
is the action space, the set of all actions available to the agent.
is the transition function, giving the probability of transitioning to state when the agent takes action in state .
is the reward function, specifying the expected immediate reward for taking action in state .
is the discount factor, which controls the relative importance of immediate versus future rewards.
The reward signal is the environment’s scalar feedback that encodes what the designer wants the agent to achieve: the agent’s objective is to maximize the expected (discounted) sum of rewards (the reward hypothesis, cf. Sutton & Barto (2018)). Rewards can be:
Sparse: e.g. +1 only when reaching the goal, and 0 otherwise (unambiguous, but can be hard to learn from).
Dense / shaped: e.g. a small step penalty or distance-to-goal bonus (easier to learn, but can introduce unintended incentives; see also the discussion of reward hacking later in this chapter).
Examples across domains:
Gridworld: terminal and 0 elsewhere.
Atari Breakout: reward is the change in game score (often clipped to in DQN-style setups).
Chess / Go: terminal reward only (+1 win, -1 loss, 0 draw), which makes credit assignment over long horizons essential.
Robotic locomotion (e.g.
HalfCheetah): shaped reward like forward velocity minus a small control-cost penalty.
The Markov property states that the future is conditionally independent of the past given the present state:
Intuitively, this holds when your state representation contains all information needed to predict what happens next. In chess, the full board configuration (including castling and en-passant flags) is Markov: how you got there does not matter for predicting legal moves and the next board position. As a counterexample, consider a driving task where your “state” is only the current position. Two situations with the same position but different velocity lead to different futures, so that representation is not Markov; adding velocity (or more generally, adding sufficient memory such as stacked frames in Atari) can restore the Markov property for the augmented state.
The agent’s goal is to find a policy that maximizes the expected discounted return:
Two central quantities in RL are the state-value function and the action-value function, defined under a policy as:
Where do the Bellman equations come from? Start from the one-step unrolling of the return,
and take expectations under to get the recursive form
Expanding that expectation using the transition function and the policy yields the familiar Bellman equation:
The optimal policy achieves the maximum value in every state. If we act optimally from the next state onward, the best action now is the one that maximizes expected immediate reward plus discounted optimal future value, giving the Bellman optimality equation:
Success Stories¶
Reinforcement learning has produced some of the most striking demonstrations of artificial intelligence. Below we highlight several landmark achievements that have shaped the field.
Playing Games¶
Games have served as the primary proving ground for reinforcement learning, offering well-defined rules, clear objectives, and increasing levels of complexity.
In 2015, Mnih et al. (2015) introduced the Deep Q-Network (DQN), which learned to play a range of Atari 2600 games directly from raw pixel inputs, achieving human-level performance on many of them. The Atari results ignited a wave of research in deep RL and established video games as a standard benchmark.
The game of Go, with its enormous search space of roughly 10170 possible board positions, had long been considered intractable for AI. In 2016, AlphaGo defeated the reigning world champion Lee Sedol Silver et al., 2016, combining deep neural networks with Monte Carlo tree search (MCTS). Its successor AlphaGo Zero learned entirely from self-play without any human data Silver et al., 2017, and AlphaZero generalized the approach to master Go, chess, and shogi with a single algorithm Silver et al., 2018.
Real-time strategy games push RL further: partial observability, continuous time pressure, enormous action spaces, and long planning horizons. In 2019, DeepMind’s AlphaStar reached Grandmaster level in StarCraft II, placing above 99.8% of human players Vinyals et al., 2019, while OpenAI Five defeated the reigning world champions at Dota 2, a five-versus-five team game requiring coordination over matches lasting roughly 45 minutes Berner et al., 2019. These results demonstrated that deep RL could scale to imperfect information, real-time decision-making, and multi-agent coordination.

Figure 3:Atari (Breakout via Gymnasium): the iconic pixel-control benchmark popularized by DQN.

Figure 4:AlphaGo and “Move 37” (from the official documentary trailer thumbnail) became a cultural moment for RL.
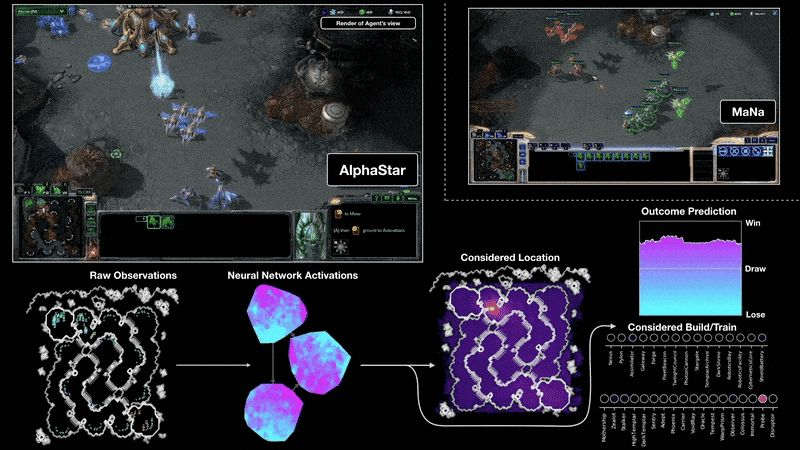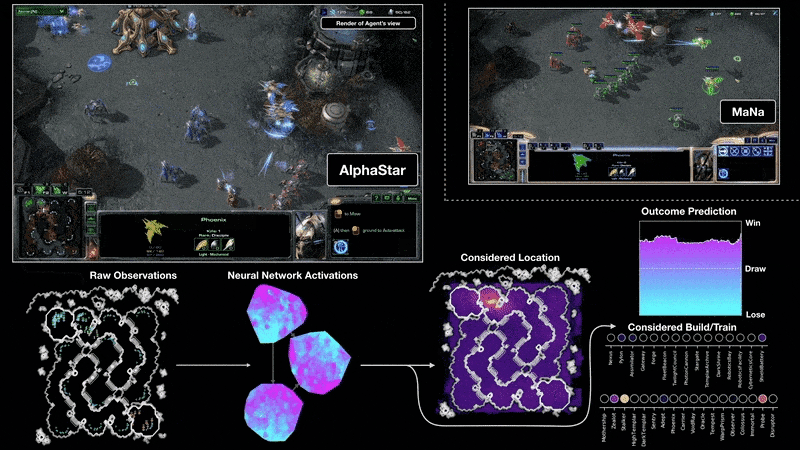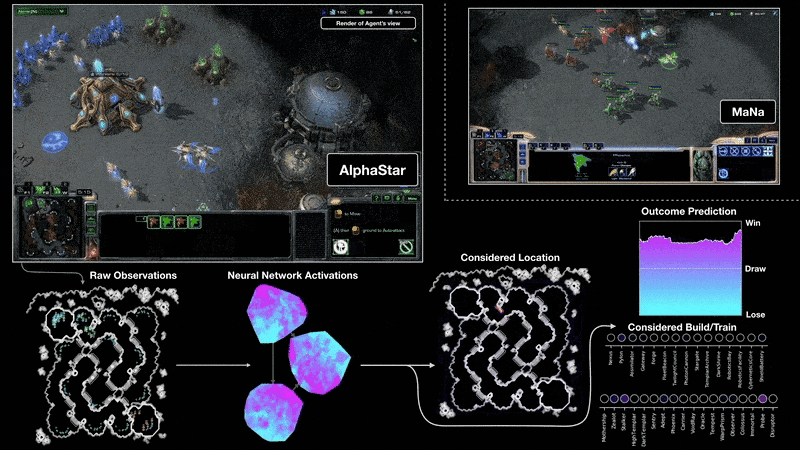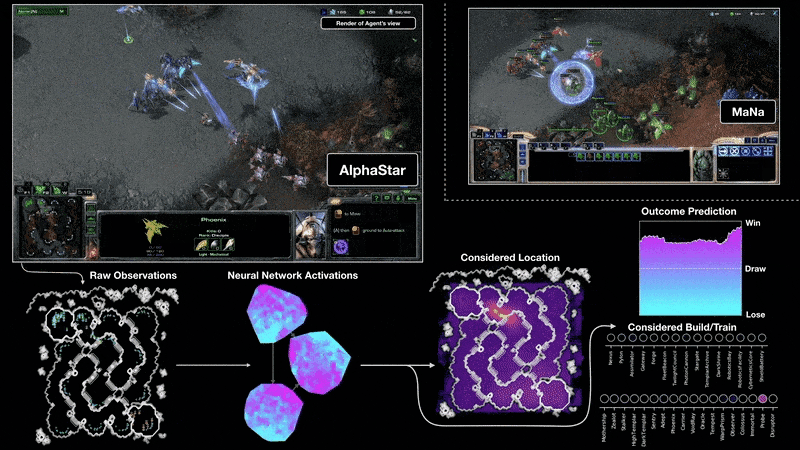
Robotics and Autonomous Driving¶
Applying RL to physical robots introduces unique challenges: noisy sensors, continuous action spaces, safety constraints, and the cost of real-world data collection. A landmark result was OpenAI’s demonstration of a robotic hand that learned to solve a Rubik’s Cube entirely in simulation and then transferred the policy to a physical robot hand Akkaya et al., 2019. The key technique — sim-to-real transfer with extensive domain randomization — showed that RL policies trained in simulation can be robust enough for dexterous manipulation in the real world. Other work showed that complex dexterous manipulation can be learned on real hardware in a few hours using model-free deep RL on low-cost platforms, with optional human demonstrations to shorten training Zhu et al., 2018. Beyond manipulation, perceptive locomotion for legged robots has been addressed with end-to-end RL: Miki et al. combined exteroceptive and proprioceptive sensing via an attention-based recurrent encoder, enabling a quadruped to traverse challenging natural and urban terrain and complete an hour-long hike in the Alps Miki et al., 2022. Autonomous driving is another high-impact domain where decisions are sequential, safety-critical, and deeply shaped by partial observability and rare events. Wayve demonstrated model-free deep RL in a real vehicle: policies map camera inputs and route traces to controls, trained end-to-end with a reward based on distance traveled before a safety-driver intervention, supplemented with simulation Kendall et al., 2019. (Hybrid imitation- and model-based planning approaches from the same line of work are an active research direction Hu et al., 2022.)

Figure 6:Dexterous manipulation: sim-to-real RL enabled a robotic hand to manipulate a Rubik’s Cube under heavy domain randomization. Image: OpenAI.

Figure 7:End-to-end driving: policies learn to map perception to control from camera inputs and route information. Cf. Kendall et al. (2019).
Managing Power Grids and Data Centers¶
RL has found impactful applications in industrial optimization. DeepMind reported large cooling-energy savings from learned control in Google data centers (popularly summarized as on the order of 40%) Evans & Gao, 2016; follow-up research describes a safe model-predictive control approach to data-center cooling Lazic et al., 2018. In the energy sector, RL agents have been explored for managing power grid operations, optimizing energy dispatch, and integrating renewable energy sources Zhang et al., 2019.
Science and Engineering¶
Beyond industrial optimization, RL has enabled breakthroughs in scientific and engineering domains where traditional optimization is intractable.
Chip design. Mirhoseini et al. (2021) used RL to automate chip floorplanning — the placement of functional blocks on a silicon die — matching or exceeding the quality of layouts produced by human experts while reducing design time from weeks to hours. The work was published in Nature and adopted in production at Google for designing tensor processing units (TPUs).

Figure 8:Overview of the method and training loop: in each iteration the RL agent places macros (large movable blocks) sequentially; after all macros are fixed, standard cells are placed with a force-directed method. Intermediate steps carry no reward; a terminal reward combines approximate wirelength, routing congestion, and cell density to update the policy. Cf. Mirhoseini et al. (2021).
Nuclear fusion plasma control. Degrave et al. (2022) applied RL to control plasma configurations inside a real tokamak fusion reactor. The RL controller learned to shape and maintain plasma in configurations that are difficult to achieve with conventional controllers, demonstrating RL’s potential in safety-critical physical systems.
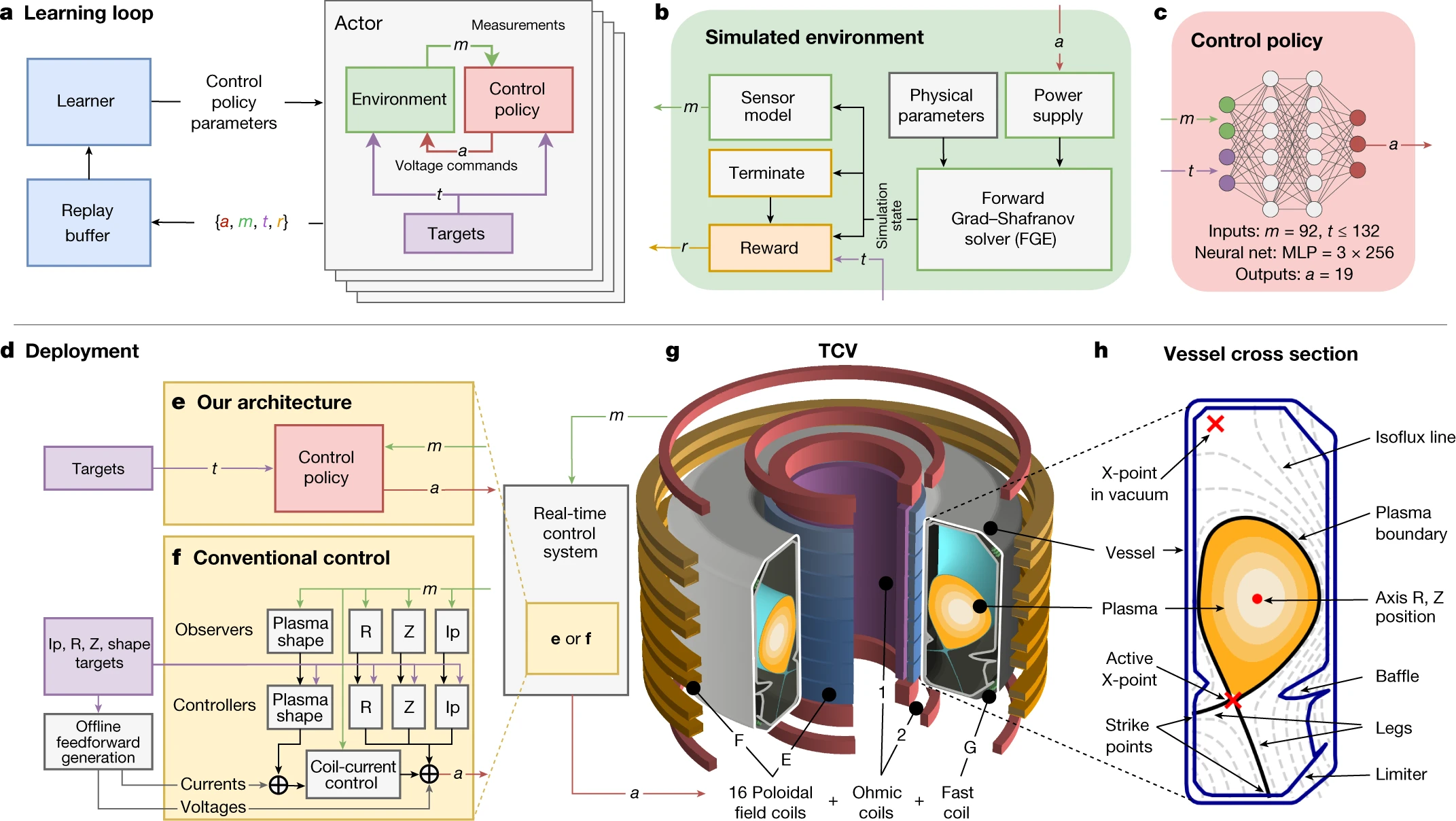
Figure 9:Schematic of the Swiss Plasma Center’s TCV tokamak: poloidal field coils and magnetic diagnostics around the vessel, the plasma boundary, and the feedback loop in which measurements are mapped by a deep RL policy to coil voltages that steer the plasma into and sustain challenging magnetic configurations. Cf. Degrave et al. (2022).
Stratospheric balloon navigation. Google’s Project Loon used RL to autonomously navigate high-altitude balloons by exploiting wind patterns at different altitudes Bellemare et al., 2020. The RL agent learned station-keeping strategies that kept balloons over target coverage areas, providing internet connectivity to remote regions.
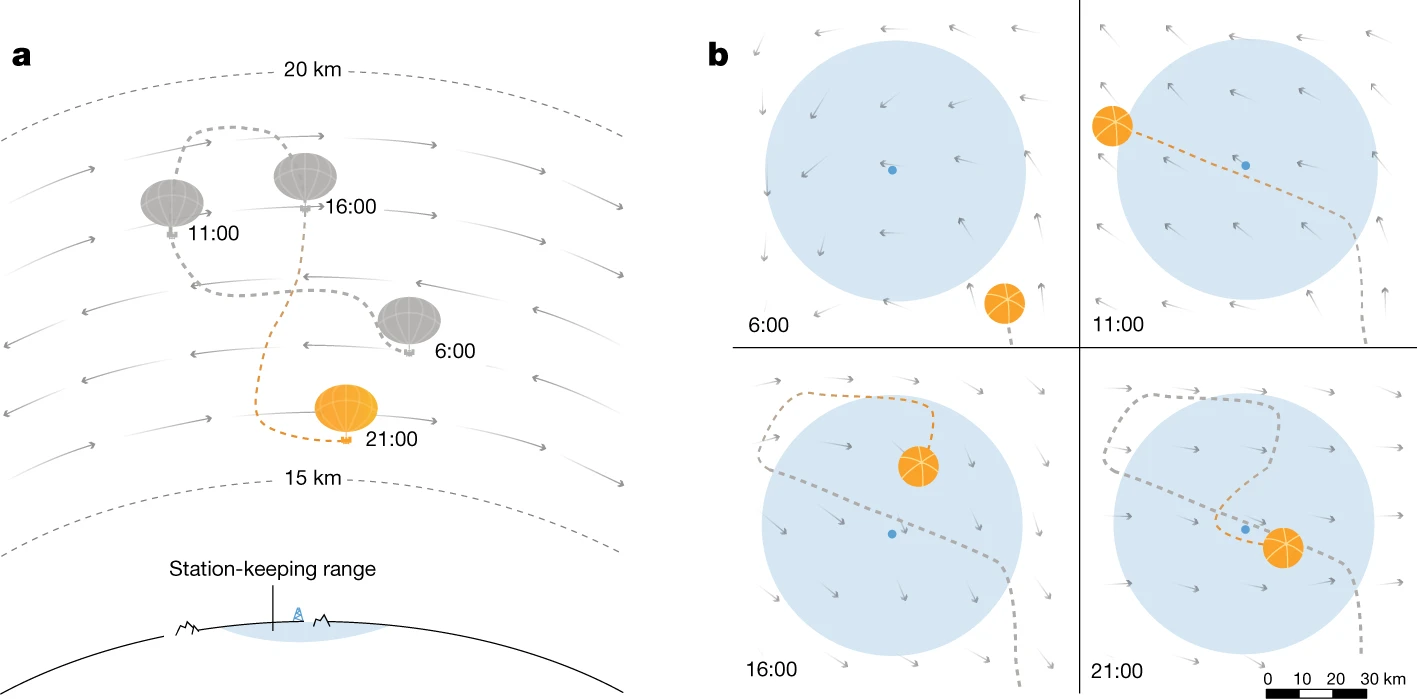
Figure 10:a, Schematic of a superpressure balloon navigating a wind field: the balloon remains near its station by moving between winds at different altitudes (dashed lines bound the altitude range). b, Top-down view of the flight path: the station and its 50 km range appear in light blue; shaded arrows indicate the wind field, which evolves over time so the balloon must replan regularly. Cf. Bellemare et al. (2020).
Drug discovery / molecular design. In molecular generation, RL agents learn to propose valid molecules that optimize multiple objectives at once (e.g., potency proxies, drug-likeness, and synthesizability). Early work demonstrated de novo design with sequence-based generative models trained with policy gradients Olivecrona et al., 2017, and later methods (e.g., MolDQN) framed molecular optimization as a Markov decision process over graph edits Zhou et al., 2019.
Large Language Models and RL¶
One of the most consequential recent applications of RL is in aligning large language models (LLMs) with human preferences. Reinforcement Learning from Human Feedback (RLHF) uses a reward model trained on human preference data to fine-tune language models via RL algorithms such as Proximal Policy Optimization (PPO) Schulman et al., 2017. This approach was central to training InstructGPT Ouyang et al., 2022 and subsequent systems like ChatGPT, making language models more helpful, harmless, and honest. RLHF has become a standard technique in the LLM pipeline and represents one of the highest-impact real-world deployments of reinforcement learning to date.
Beyond alignment, RL is now used to improve the reasoning capabilities of large language models. DeepSeek-R1 demonstrated that RL with verifiable rewards — where correctness can be checked automatically, as in mathematics and code — can train models to produce explicit chains of thought, substantially improving performance on reasoning benchmarks Guo & others, 2025. Similar ideas underpin OpenAI’s o1 and o3 models. This line of work shows that RL can shape not just what a model says but how it thinks, and represents one of the most active frontiers in AI research.
What Makes Reinforcement Learning Difficult and Interesting?¶
Despite its successes, RL remains one of the most challenging areas of machine learning. Several fundamental challenges pervade the field, and understanding them is essential before diving into algorithms.
Exploration / Exploitation Trade-off¶
An RL agent faces a constant dilemma: should it exploit its current knowledge to maximize immediate reward, or explore new actions that might lead to even better outcomes? This is the exploration-exploitation trade-off, one of the most studied problems in decision theory Sutton & Barto, 2018.
Consider a simple example: a robot navigating a maze has found a path that yields some reward. Should it keep following this known path (exploit), or try unexplored corridors that might lead to a larger reward (explore)?
If the agent explores too little, it may converge to a suboptimal policy, never discovering better strategies. If it explores too much, it wastes time on unpromising actions. Balancing exploration and exploitation is particularly difficult in environments with:
Sparse rewards: The agent receives non-zero reward only rarely, making it hard to discover rewarding behavior at all.
Large state spaces: With many possible states, systematic exploration becomes computationally expensive.
Deceptive rewards: Local optima that provide moderate reward but prevent the agent from reaching globally optimal behavior.
The simplest and most widely used exploration heuristic is -greedy action selection, which chooses a random action with probability and the greedy action otherwise Sutton & Barto, 2018. More principled classical strategies include Upper Confidence Bound (UCB) methods Auer et al., 2002 and Thompson sampling. In deep RL, scaling exploration to high-dimensional state spaces has motivated a rich family of approaches — from intrinsic motivation and curiosity-driven bonuses Pathak et al., 2017 to count-based methods, noisy networks, and archive-based algorithms such as Go-Explore Ecoffet et al., 2021. For a comprehensive taxonomy, see the survey by Ladosz et al. Ladosz et al., 2022.
Credit Assignment Problem¶
The credit assignment problem asks: when the agent receives a reward, which of its past actions were responsible? In environments with delayed rewards, a reward received at time step may be the consequence of an action taken many steps earlier. Correctly attributing credit to the right actions is essential for learning effective policies.
For example, in a game of chess, the final reward (win or loss) depends on decisions made throughout the entire game. The challenge of determining which moves were critical to the outcome — and which were irrelevant — is the credit assignment problem in its temporal form.
Temporal-difference (TD) learning Sutton, 1988 addresses this by bootstrapping value estimates, propagating reward information backwards through time. More advanced methods include eligibility traces (e.g., TD()) for multi-step credit Sutton & Barto, 2018 and generalized advantage estimation (GAE) Schulman et al., 2016 for bias–variance tradeoffs in advantage estimates for policy learning.
Sample Efficiency¶
Sample efficiency measures how much environment interaction an agent needs to reach good performance. Deep RL agents often require orders of magnitude more data than supervised learners for comparable progress: for example, the original DQN Nature experiments trained for 50 million frames per game in their main setting (with shorter runs such as 10 million frames reported in some analyses) Mnih et al., 2015, whereas a human can learn many of the same games from minutes of play. This gap is not merely a nuisance — collecting real-world trials on robots or in production systems can be slow, expensive, or unsafe, which makes sample efficiency a central bottleneck for deployment.
Several research directions aim to reduce the interaction burden. Model-based RL learns a dynamics model and plans or imagines in that model to improve data efficiency Deisenroth & Rasmussen, 2011Hafner et al., 2025. Offline RL learns policies from fixed logged datasets without further online interaction Fu et al., 2020. Representation-learning approaches such as self-predictive representations can improve data efficiency in the low-data regime Schwarzer et al., 2021. Even with these advances, DRL remains far more sample-hungry than typical supervised learning in comparable input dimensions.
Stability and Reproducibility¶
Training deep RL systems is notoriously unstable and sensitive to implementation details. Sutton and Barto discuss the deadly triad: the combination of function approximation, bootstrapping (e.g., TD targets), and off-policy learning can lead to divergence or pathological value estimates Sutton & Barto, 2018. Even when algorithms avoid outright divergence, high variance across random seeds, environment stochasticity, and hyperparameter choices is common.
Henderson et al. (2018) systematically studied this issue and argued that reported improvements in deep RL are often difficult to interpret without rigorous experimental protocols: changing only the random seed can swing performance from failure to strong results for standard algorithms. Complementary algorithmic ideas target specific failure modes — for instance, Double DQN reduces overestimation bias in value learning Hasselt et al., 2016 — but stability and reproducibility remain active practical concerns for practitioners.
Reward Design and Reward Hacking¶
In RL, the reward function is the complete specification of what the agent should optimize. In practice, specifying rewards that faithfully encode human intent is difficult: sparse rewards give little learning signal, while dense shaping rewards can inadvertently teach the wrong behavior. When the formal objective differs even slightly from the designer’s true goal, agents may reward hack — optimizing the stated metric in unintended ways (a manifestation of Goodhart’s law). Concrete Problems in AI Safety Amodei et al., 2016 catalogs examples including safe exploration, avoiding side effects, and scalable oversight, alongside reward misspecification.
Potential-based reward shaping provides principled ways to add auxiliary rewards without changing optimal policies under mild conditions Ng et al., 1999. At scale, RL from human feedback trains a reward model from preferences and uses RL to align behavior with that model Ouyang et al., 2022 — a partial answer to the difficulty of hand-crafting rewards, though it introduces new questions about reward-model quality and distribution shift.
Generalization¶
Classical RL theory often assumes training and testing on the same MDP. In deep RL, agents frequently overfit to idiosyncrasies of the training simulator — particular level layouts, textures, or dynamics — and fail when those details change. Cobbe et al. (2019) introduced procedurally generated benchmarks (e.g., CoinRun) to separate training and test levels and showed that agents can require surprisingly many training levels before generalizing. Follow-up work on larger procedural suites Cobbe et al., 2020 reinforced that train/test splits for environments are as important as in supervised learning. Diagnostic studies in continuous control similarly emphasize training diversity and careful evaluation protocols when assessing generalization Zhang et al., 2018.
Safety and Constraint Satisfaction¶
Many real-world tasks require maximizing return subject to constraints: a robot must avoid collisions, a vehicle must respect traffic rules, or a system must stay within power or latency budgets. The standard MDP objective does not express such requirements directly; constrained MDPs (CMDPs) extend the framework with auxiliary costs and constraints Altman, 1999. Safe reinforcement learning surveys formulations that enforce safety during learning or deployment, modify exploration to reduce catastrophic trials, or combine RL with shields and prior knowledge García & Fernández, 2015. Constrained policy optimization (CPO) is an example of a policy-search method that approximately enforces cost constraints during training Achiam et al., 2017. Safety connects naturally to reward design Amodei et al., 2016: hard constraints can encode requirements that are awkward or fragile to express purely through rewards.
Ecosystem¶
Research Environments¶
Standardized environments are critical for benchmarking RL algorithms and ensuring reproducible research.
Gymnasium (formerly OpenAI Gym)¶


The de facto standard API for RL environments Brockman et al., 2016Towers et al., 2024. Gymnasium provides a simple and consistent interface (reset, step, render) and a broad task collection spanning low-dimensional control, physics-based benchmarks, and symbolic/discrete domains. In practice, these families are often used at different stages: classic control for debugging, Box2D for richer continuous dynamics, ToyText for studying tabular/DP-style learning behavior, and MuJoCo locomotion tasks (e.g., HalfCheetah, Ant, Humanoid) for high-dimensional continuous control Todorov et al., 2012.
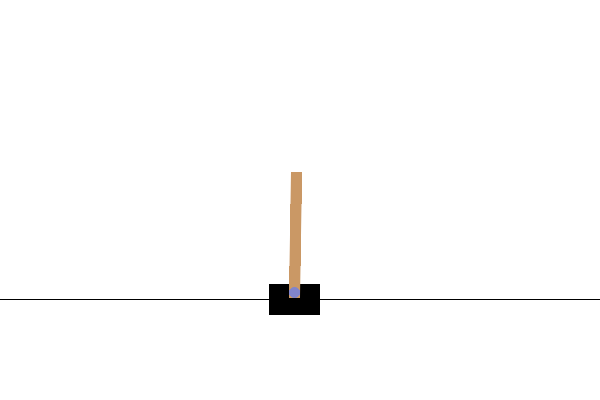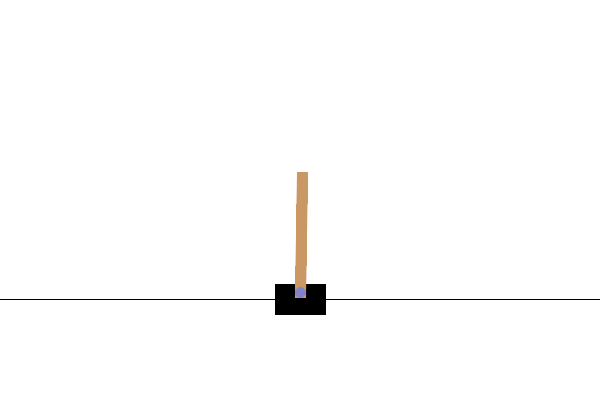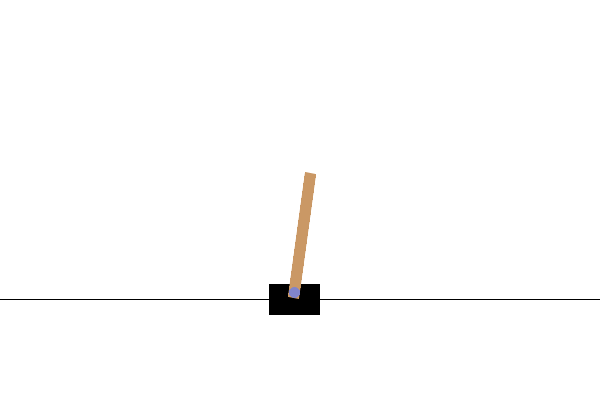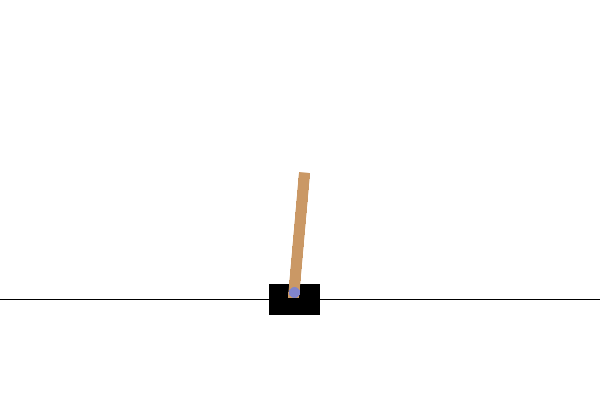 |  |  |
| Classic Control (`CartPole`): a compact low-dimensional benchmark. | Box2D (`LunarLander`): contact-rich 2D physics with more challenging optimization and exploration dynamics. | ToyText (`FrozenLake`): a discrete stochastic MDP ideal for tabular RL and dynamic-programming intuition. |
 |  |  |
| MuJoCo (`HalfCheetah`): a classic 2D locomotion benchmark for continuous-control RL. | MuJoCo (`Ant`): 3D quadruped locomotion with contact-rich dynamics and stability challenges. | MuJoCo (`Humanoid`): high-dimensional bipedal control with complex coordination. |
Atari / Arcade Learning Environment (ALE)¶


The Arcade Learning Environment (ALE) provides a large suite of Atari 2600 games and has been one of the most influential visual-control benchmarks in deep RL Bellemare et al., 2013. In modern workflows, Atari environments are commonly accessed through Gymnasium wrappers, so they integrate with the same reset/step API used elsewhere. In these tasks, observations are image frames (screenshots) from the game. A common full-benchmark protocol evaluates 57 Atari games, while the Atari 100k protocol focuses on 26 games under a strict 100,000-interaction budget Kaiser et al., 2020.
 | |  |
| `Pong`: reactive control and timing. | `Breakout`: precision control with sparse-score dynamics. | `Hero`: long-horizon exploration and delayed rewards. |
DeepMind Control Suite (DMControl)¶


A set of continuous-control benchmark tasks built on the MuJoCo physics engine Todorov et al., 2012, exposing domains such as locomotion, manipulation, and balance with well-defined state/action interfaces. DMControl emphasizes reproducibility through standardized task definitions, consistent reward specifications, and reference implementations that make cross-paper comparisons more reliable Tassa et al., 2018.
 DMControl is a MuJoCo-based benchmark suite for continuous-control RL, designed to provide standardized tasks, reward structures, and evaluation settings so algorithms can be compared consistently across locomotion, manipulation, and balance problems.
DMControl is a MuJoCo-based benchmark suite for continuous-control RL, designed to provide standardized tasks, reward structures, and evaluation settings so algorithms can be compared consistently across locomotion, manipulation, and balance problems.
PettingZoo¶


An extension of the Gymnasium API to multi-agent reinforcement learning (MARL) Terry et al., 2021. While standard RL considers a single agent optimizing its own cumulative reward, MARL studies settings where multiple agents act in a shared environment—each with its own observations, actions, and objectives. Agents may need to cooperate toward a common goal, compete against one another, or navigate mixed incentive structures where cooperation and competition coexist. This shift introduces fundamentally new challenges: non-stationarity (each agent’s optimal policy depends on the evolving policies of others), multi-agent credit assignment, and the emergence of communication or coordination strategies.
PettingZoo organizes its environments into five families:
Atari — Multi-player variants of classic Atari 2600 games (e.g., Pong, Space Invaders, Warlords) adapted for two or more competing or cooperating agents, with pixel observations.
Butterfly — Pygame-based cooperative environments (Cooperative Pong, Knights Archers Zombies, Pistonball) that require highly coordinated emergent behaviors and present Atari-style visual observations.
Classic — Turn-based board and card games (Chess, Go, Connect Four, Texas Hold’em, Hanabi, etc.) posing competitive or cooperative challenges with discrete action spaces and perfect- or imperfect-information dynamics.
MPE (Multi-Particle Environments) — Communication-oriented 2D particle worlds (Simple Spread, Simple Tag, Simple Adversary, etc.), originally from OpenAI Lowe et al., 2017, where agents move, communicate, and interact with landmarks in cooperative or adversarial settings.
SISL (Stanford Intelligent Systems Laboratory) — Continuous-control cooperative benchmarks (Multiwalker, Pursuit, Waterworld) from Gupta et al., 2017, emphasizing coordination through physics-based locomotion and pursuit-evasion dynamics.
 |  | ||
| Butterfly (`Pistonball`): cooperative physics-based coordination with pixel observations. | Classic (`Chess`): competitive turn-based strategy with perfect information. | MPE (`Simple Spread`): cooperative particle navigation with communication channels. | SISL (`Waterworld`): cooperative continuous-control pursuit with sensor-based observations. |
MiniGrid¶


A lightweight, fast grid-world environment suite designed for research on goal-conditioned RL, curriculum learning, exploration, and generalization Chevalier-Boisvert et al., 2023. Each environment is a partially observable 2D grid where a triangle-shaped agent must navigate rooms, interact with objects (keys, doors, boxes), and reach goals using a small discrete action space. The partial observability (the agent sees only a limited forward cone) and procedural generation of layouts make these tasks a compelling testbed for memory, planning, and transfer. The library also includes the BabyAI environments, which pair grid-world navigation with natural-language instructions, enabling research on language-conditioned and instruction-following RL. All environments are programmatically tunable in size and complexity, making them well-suited for curriculum learning.
 |  | 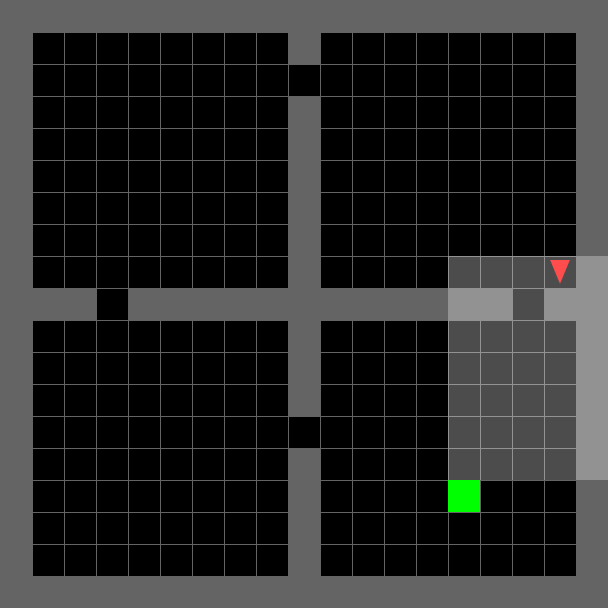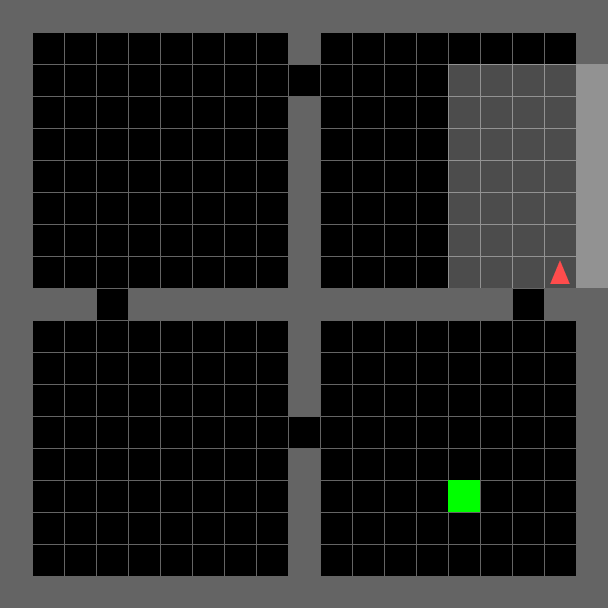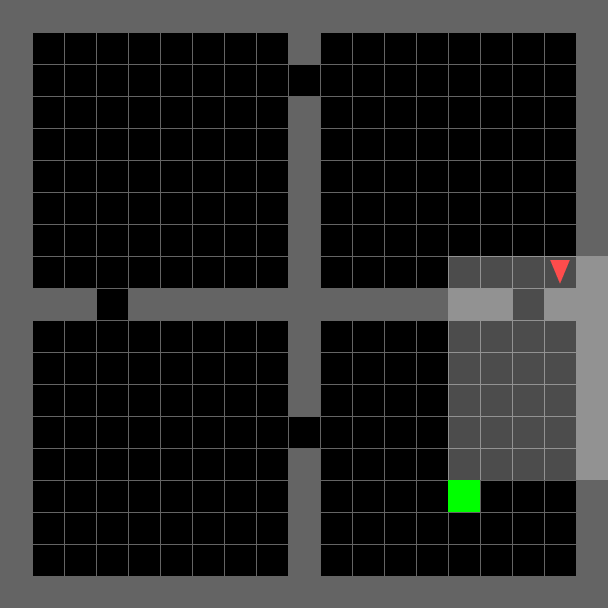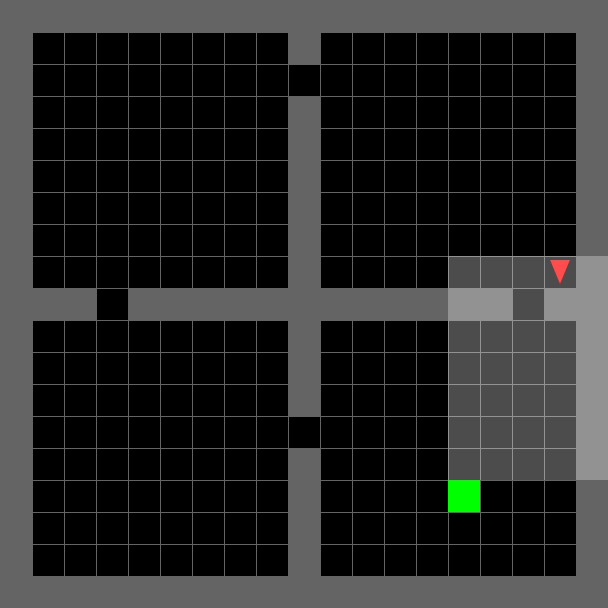 |  |
| `EmptyEnv`: minimal navigation for prototyping and sanity-checking algorithms. | `DoorKeyEnv`: sequential sub-goal reasoning—pick up key, unlock door, reach goal. | `FourRoomsEnv`: multi-room exploration requiring long-horizon planning under partial observability. | `DynamicObstaclesEnv`: reactive navigation among moving obstacles. |
Procgen Benchmark¶


The Procgen Benchmark is a suite of 16 procedurally generated, game-like environments designed to evaluate both sample efficiency and (crucially) generalization in deep RL Cobbe et al., 2020. Each environment can generate large numbers of distinct levels, enabling a clean separation between training levels and held-out test levels—a useful stress test for overfitting when learning from pixels.
 |  |  |  |
| `CoinRun`: a platformer benchmark popular for measuring train/test level generalization. | `StarPilot`: reactive control under dense visual clutter and moving hazards. | `BigFish`: survival and risk management—eat smaller fish, avoid larger ones. | `Heist`: long-horizon navigation with keys/locks and sparse success signals. |
D4RL / Minari (Offline RL)¶


Offline reinforcement learning studies learning a policy from a fixed dataset of past experience, without further interaction during training. The D4RL benchmark popularized standardized offline datasets spanning locomotion, navigation, and manipulation tasks Fu et al., 2020. Today, many D4RL-style datasets are distributed and maintained via Minari, a standard dataset API for offline RL maintained by the Farama Foundation The Farama Foundation, 2023.
 |  |  |
| `AntMaze`: long-horizon navigation with sparse success, using a MuJoCo ant quadruped. | `FrankaKitchen`: multi-step manipulation with compositional goals (microwave, cabinets, kettle, etc.). | `AdroitHandDoor`: dexterous, contact-rich manipulation with demonstrations and suboptimal data. |
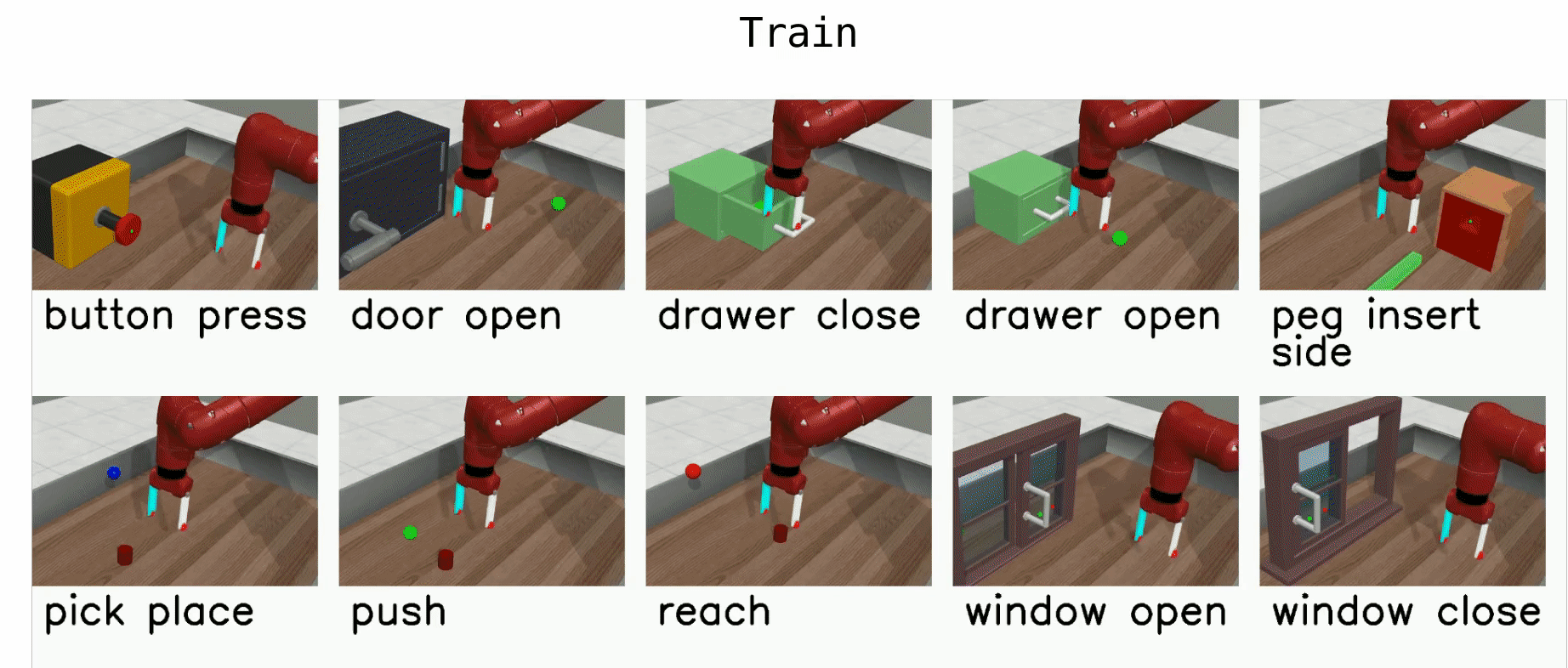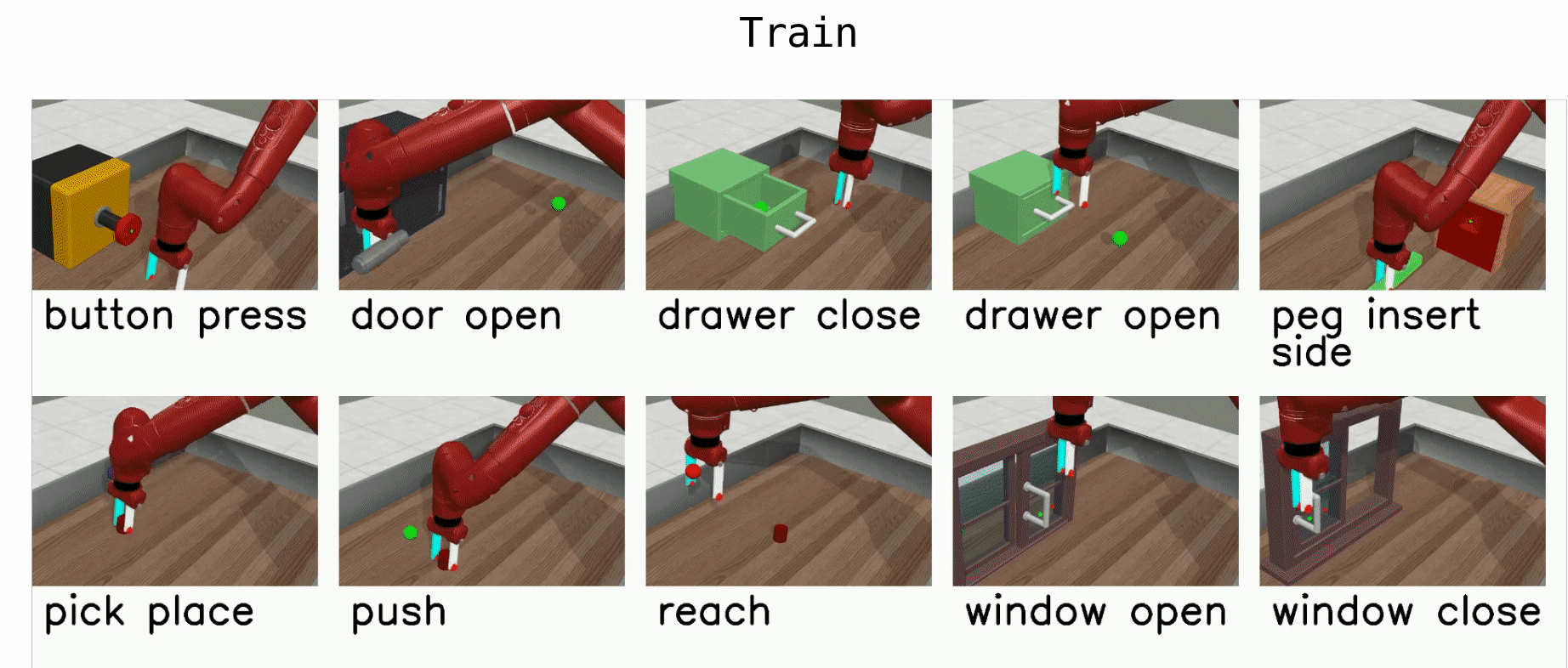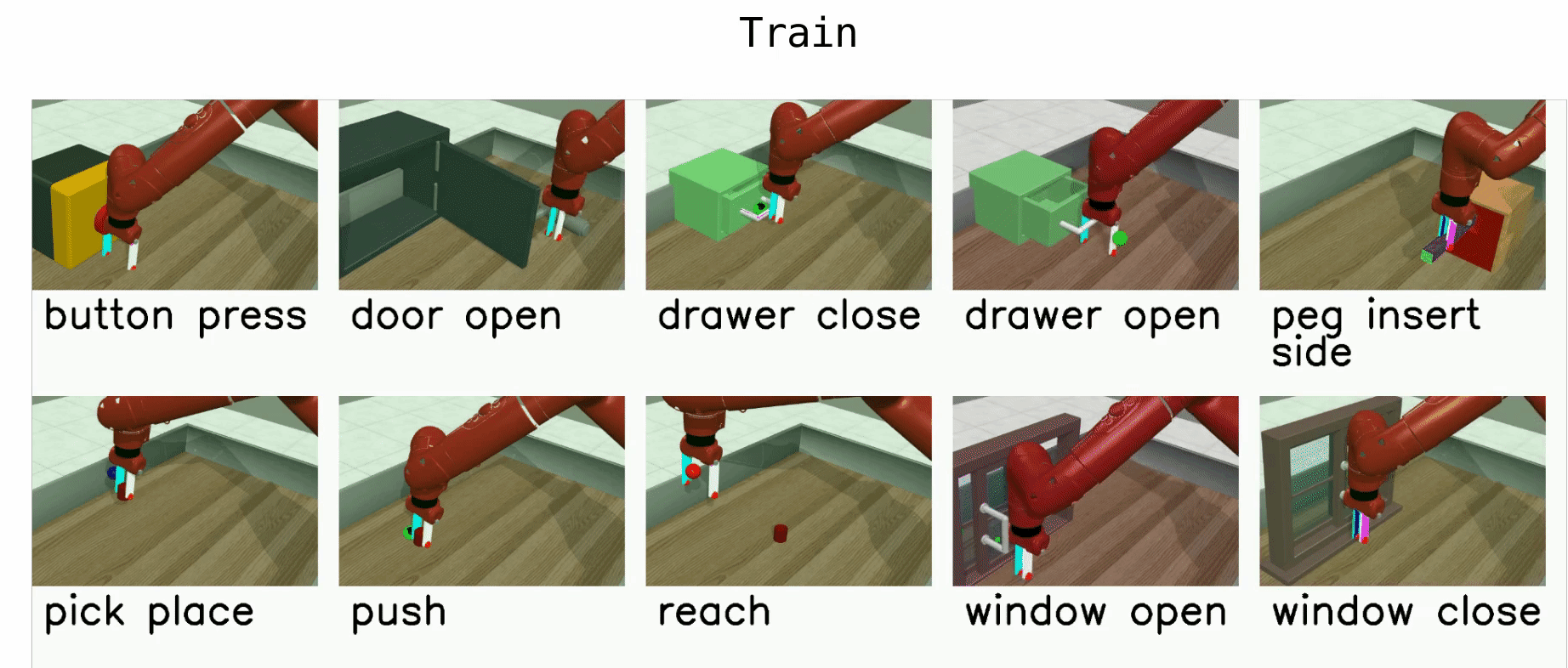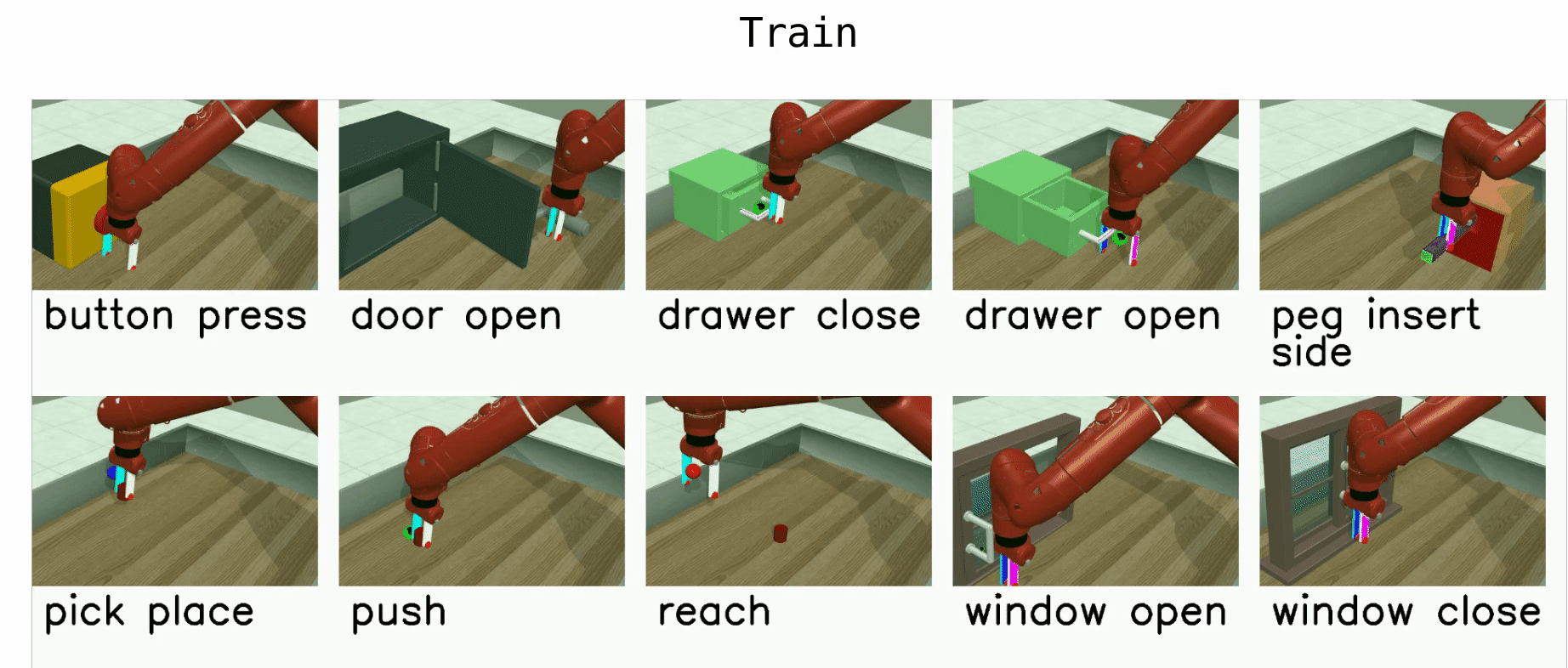
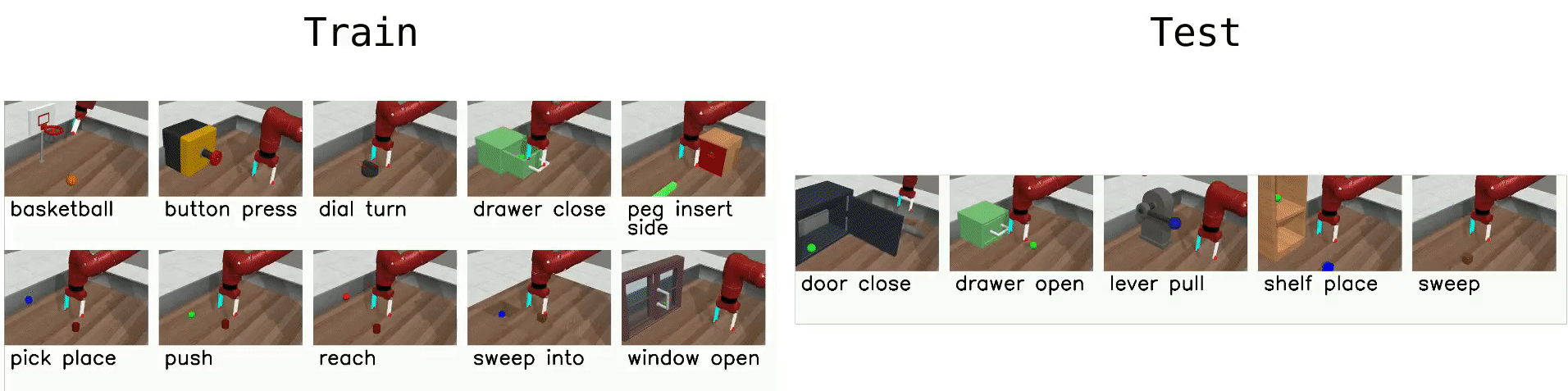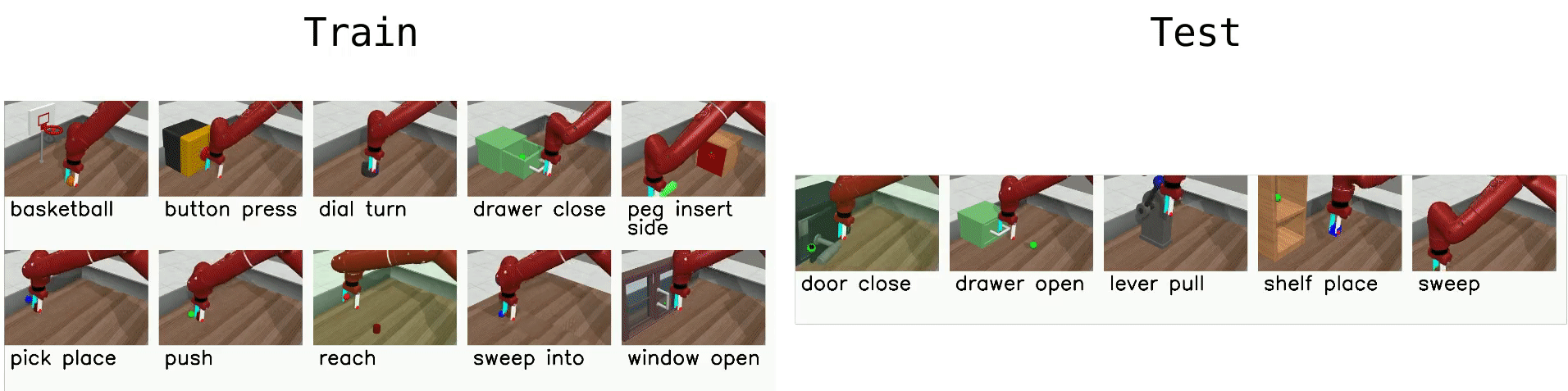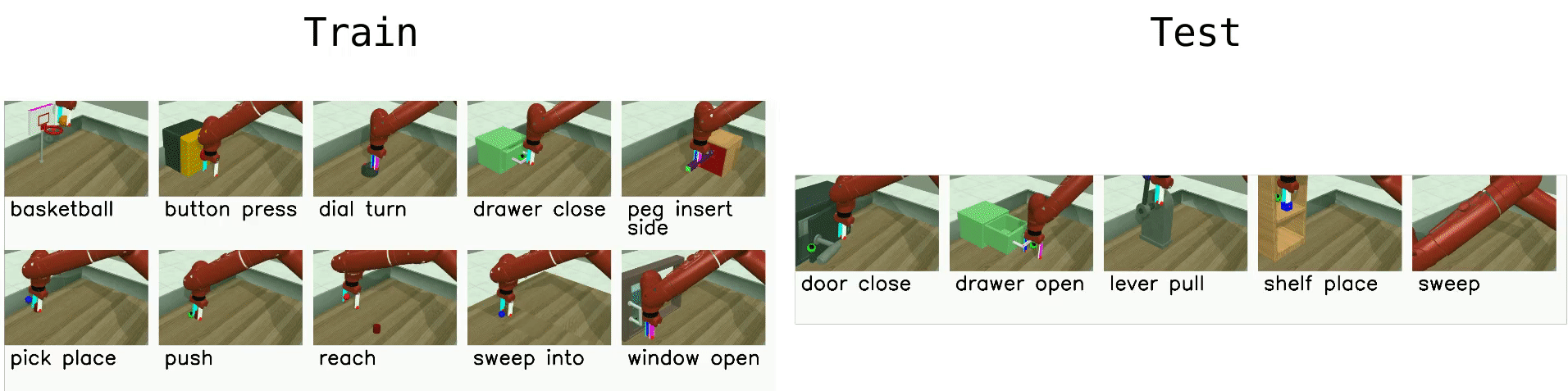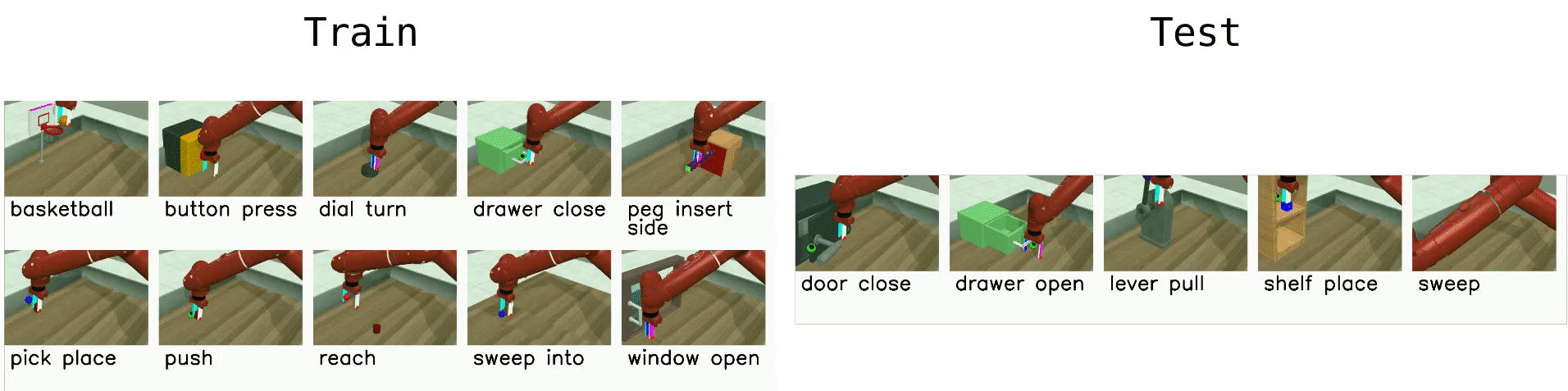
Meta-World¶


Meta-World is a robotics benchmark with 50 simulated manipulation tasks designed for multi-task RL and meta-RL Yu et al., 2020. It provides standardized evaluation protocols (MT1/MT10/MT50 for multi-task learning and ML1/ML10/ML45 for meta-learning), making it a common testbed for studying transfer, adaptation, and learning shared representations across tasks.
 |  |
| Multi-task: learn a single policy across diverse manipulation tasks. | Meta-learning: adapt quickly to new tasks or goal variations at test time. |
Isaac Lab¶


Isaac Lab is a GPU-accelerated open-source framework for robot learning built on NVIDIA Isaac Sim, with an emphasis on large-scale parallel simulation (many environments on a single GPU), realistic sensors, and sim-to-real workflows Mittal et al., 2025. It includes ready-to-train environments spanning legged locomotion, manipulation, navigation, and multi-agent settings.
 Isaac Lab focuses on scalable GPU-parallel robotics simulation and training workflows built on Isaac Sim.
Isaac Lab focuses on scalable GPU-parallel robotics simulation and training workflows built on Isaac Sim.
Algorithm Libraries¶
The RL ecosystem offers several mature libraries. The table below compares the most popular options.
Table 1:Comparison of popular RL libraries.
Library | GitHub | Description | Advantages | Disadvantages |
|---|---|---|---|---|
| Reliable implementations of standard RL algorithms Raffin et al., 2021 | Easy to use; well-tested; good documentation; Gymnasium-compatible | Limited algorithm selection; less flexible for research on novel methods | |
| PyTorch-native RL library Bou et al., 2023 | Modular design; tight PyTorch integration; composable components; actively developed | Steeper learning curve; younger project with evolving API | |
| Single-file implementations of RL algorithms Huang et al., 2022 | Highly readable; great for learning and research; easy to modify | Not designed for production use; less abstraction | |
| Modular PyTorch RL library with broad algorithm coverage Weng et al., 2022 | Wide algorithm selection (including offline RL); clean API; good balance of usability and flexibility | Smaller community than SB3; less integrated than TorchRL for PyTorch-native workflows | |
| Scalable RL library built on Ray Liang et al., 2018 | Distributed training; multi-agent support; production-ready | Complex API; heavy dependencies; steep learning curve |










Textbooks and Lectures¶
The following resources provide deeper coverage of the topics introduced in this course.
Textbooks¶
Sutton & Barto (2018) — Reinforcement Learning: An Introduction Sutton & Barto, 2018. The standard reference for RL. Covers bandits, MDPs, dynamic programming, Monte Carlo methods, TD learning, and function approximation / Deep RL. Freely available online.
Bertsekas (2019; 2025) — Reinforcement Learning and Optimal Control Bertsekas, 2019 and A Course in Reinforcement Learning (2nd ed.) Bertsekas, 2025. Bridges RL with the optimal control and dynamic programming traditions. Rigorous and mathematically oriented; the course notes are freely available.
Szepesvari (2010) — Algorithms for Reinforcement Learning Szepesvári, 2010. A concise monograph covering the theoretical foundations of RL algorithms. Excellent for readers seeking a compact, precise treatment.
Agarwal et al. (2022+) — Reinforcement Learning: Theory and Algorithms Agarwal et al., 2022. A graduate-level theory-focused monograph (sample complexity, function approximation, offline RL). Freely available online.
Plaat (2022) — Deep Reinforcement Learning, a textbook Plaat, 2022. A comprehensive overview of deep RL, with an arXiv preprint.
Lecture Series¶
DeepMind x UCL RL Lecture Series (2021) — A modern, high-quality lecture series covering foundations through deep RL.
Sergey Levine’s Deep RL Course (CS 285) — Covers deep RL with a focus on continuous control and modern policy gradient methods (see also the lecture playlist).
Emma Brunskill’s RL Course (CS 234) — Emphasizes both foundations and applications (incl. healthcare and education) (see also the lecture playlist).
Pieter Abbeel’s Foundations of Deep RL — A compact 6-lecture series that connects core RL concepts to modern deep RL methods.
Online Courses¶
Hugging Face Deep Reinforcement Learning Course — Free, self-paced, and hands-on (theory + practical assignments).
Reinforcement Learning Specialization (University of Alberta, Coursera) — A structured 4-course sequence aligned with Sutton & Barto.
OpenAI Spinning Up in Deep RL — A tutorial-style resource with clear algorithm implementations and conceptual guides.
Summary¶
In this chapter we introduce reinforcement learning (RL) as learning to act through interaction: an agent chooses actions, observes next states, and receives rewards, aiming to maximize cumulative (discounted) return. We formalize the problem as a Markov Decision Process (MDP) , where the Markov property enables recursive (Bellman) equations for reasoning about long-term consequences. We highlight the central objects—policies , value functions , and action-values —and connect optimal control to finding via Bellman optimality. We then motivate modern “deep RL”, where neural networks represent policies and/or value functions in high-dimensional domains, and we summarize why RL remains challenging in practice (exploration, delayed credit assignment, non-stationarity, and partial observability), making solid tooling and benchmarks (Gymnasium, TorchRL, CleanRL, etc.) key for reproducible experiments.
- Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction (2nd ed.). MIT Press. http://incompleteideas.net/book/the-book-2nd.html
- Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidjeland, A. K., Ostrovski, G., Petersen, S., Beattie, C., Sadik, A., Antonoglou, I., King, H., Kumaran, D., Wierstra, D., Legg, S., & Hassabis, D. (2015). Human-Level Control through Deep Reinforcement Learning. Nature, 518(7540), 529–533. 10.1038/nature14236
- Fukushima, K. (1980). Neocognitron: A Self-Organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position. Biological Cybernetics, 36(4), 193–202. 10.1007/BF00344251
- LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-Based Learning Applied to Document Recognition. Proceedings of the IEEE, 86(11), 2278–2324. 10.1109/5.726791
- Puterman, M. L. (1994). Markov Decision Processes: Discrete Stochastic Dynamic Programming. John Wiley & Sons.
- Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., van den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M., Dieleman, S., Grewe, D., Nham, J., Kalchbrenner, N., Sutskever, I., Lillicrap, T., Leach, M., Kavukcuoglu, K., Graepel, T., & Hassabis, D. (2016). Mastering the Game of Go with Deep Neural Networks and Tree Search. Nature, 529(7587), 484–489. 10.1038/nature16961
- Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., Hubert, T., Baker, L., Lai, M., Bolton, A., Chen, Y., Lillicrap, T., Hui, F., Sifre, L., van den Driessche, G., Graepel, T., & Hassabis, D. (2017). Mastering the Game of Go without Human Knowledge. Nature, 550(7676), 354–359. 10.1038/nature24270
- Silver, D., Hubert, T., Schrittwieser, J., Antonoglou, I., Lai, M., Guez, A., Lanctot, M., Sifre, L., Kumaran, D., Graepel, T., Lillicrap, T., Simonyan, K., & Hassabis, D. (2018). A General Reinforcement Learning Algorithm that Masters Chess, Shogi, and Go through Self-Play. Science, 362(6419), 1140–1144. 10.1126/science.aar6404
- Vinyals, O., Babuschkin, I., Czarnecki, W. M., Mathieu, M., Dudzik, A., Chung, J., Choi, D. H., Powell, R., Ewalds, T., Georgiev, P., Oh, J., Horgan, D., Kroiss, M., Danihelka, I., Huang, A., Sifre, L., Cai, T., Agapiou, J. P., Jaderberg, M., … Silver, D. (2019). Grandmaster Level in StarCraft II Using Multi-Agent Reinforcement Learning. Nature, 575(7782), 350–354. 10.1038/s41586-019-1724-z
- Berner, C., Brockman, G., Chan, B., Cheung, V., Dębiak, P., Dennison, C., Farhi, D., Fischer, Q., Hashme, S., Hesse, C., Józefowicz, R., Gray, S., Olsson, C., Pachocki, J., Petrov, M., de Oliveira Pinto, H. P., Raiman, J., Salimans, T., Schlatter, J., … Zhang, S. (2019). Dota 2 with Large Scale Deep Reinforcement Learning. arXiv Preprint arXiv:1912.06680.
- Akkaya, I., Andrychowicz, M., Chociej, M., Litwin, M., McGrew, B., Petron, A., Paino, A., Plappert, M., Powell, G., Ribas, R., Schneider, J., Tezak, N., Tworek, J., Welinder, P., Weng, L., Yuan, Q., Zaremba, W., & Zhang, L. (2019). Solving Rubik’s Cube with a Robot Hand. arXiv Preprint arXiv:1910.07113.
- Zhu, H., Gupta, A., Rajeswaran, A., Levine, S., & Kumar, V. (2018). Dexterous Manipulation with Deep Reinforcement Learning: Efficient, General, and Low-Cost. arXiv Preprint arXiv:1810.06045.
- Miki, T., Lee, J., Hwangbo, J., Wellhausen, L., Koltun, V., & Hutter, M. (2022). Learning Robust Perceptive Locomotion for Quadrupedal Robots in the Wild. Science Robotics, 7(62). 10.1126/scirobotics.abk2822
- Kendall, A., Hawke, J., Janz, D., Mazur, P., Reda, D., Allen, J.-M., Lam, V.-D., Bewley, A., & Shah, A. (2019). Learning to Drive in a Day. IEEE International Conference on Robotics and Automation (ICRA), 8248–8254. 10.1109/ICRA.2019.8793742
- Hu, A., Corrado, G., Griffiths, N., Murez, Z., Gurau, C., Yeo, H., Kendall, A., Cipolla, R., & Shotton, J. (2022). Model-Based Imitation Learning for Urban Driving. Advances in Neural Information Processing Systems, 35. https://arxiv.org/abs/2210.07729